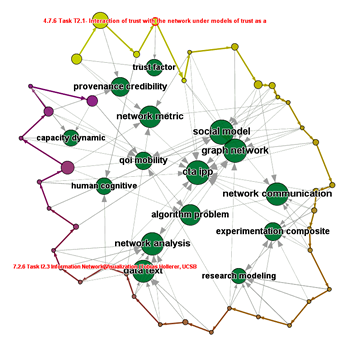
Figure 3: TopicNets visualization of entire CTA Initial Program Plan (IPP). First section starts in yellow at top left, last section ends in purple at nearly full circle. Two Sections (== subtasks) have been selected (red labels).
Scalable, Human-Centric Information Network Systems
A central characteristic of information/social networks is that it facilitates rapid dissemination of information between social entities. We examined the problem of determination of information flow representatives, a small group of authoritative representatives to whom the dissemination of a piece of information leads to the maximum spread. Information flow is affected by a number of different structural factors such as the node degree, connectivity, intensity of information flow interaction and the global structural behavior of the underlying network. We proposed a stochastic information flow model, and used it to determine the authoritative representatives in the underlying social network. We designed an accurate RankedReplace algorithm, and then used a Bayes probabilistic model in order to approximate the effectiveness of this algorithm with the use of a fast algorithm. The proposed method was shown extremely effective and efficient in determining intuitively authoritative representatives in the network. (Aggarwal et al. 2010)
The identification of clusters, well-connected components in a network is useful in many applications from biological function prediction to social community detection. However, finding these clusters can be difficult as graph sizes increase. Most of the existing graph clustering algorithms scale poorly in terms of time or memory. An important insight is that many clustering applications need only the subset of most strongly connected clusters, and not all clusters in the entire graph. Marcopol and Singh proposed a new model, Top Graph Clusters (TopGC), which probabilistically searches large, edge-weighted, directed graphs for their most strongly connected clusters in linear time. The algorithm is inherently parallelizable, and is able to find variable size, overlapping clusters. When compared with three other state-of-the art clustering techniques, TopGC achieves running time speedups of up to 70% on large scale real world datasets. In addition, the clusters returned by TopGC are consistently found to be better both in calculated score and when compared on real world benchmarks. (Macropol and Singh 2010)
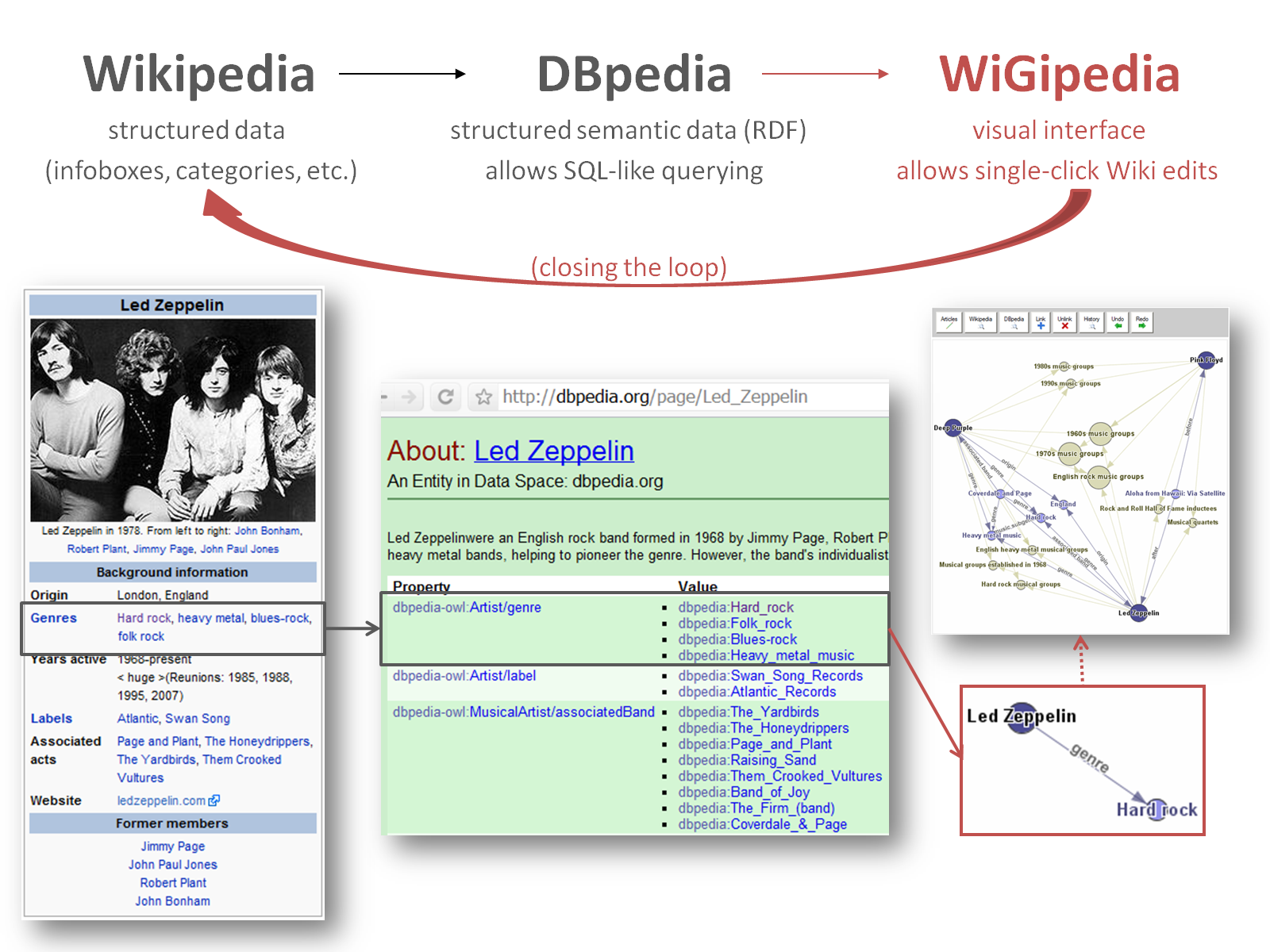
We have had great success furthering people's understanding of large heterogeneous information networks through development of an interactive tool for analyzing topic-based relations among large text collections. Through an external collaboration with Topic Modeling experts at UC Irvine, we have adapted our graph visualization framework, WiGis, to support visualization of output from an LDA algorithm, by mapping LDA output (Topics, Documents and probabilistic association data) onto various dimensions of an interactive graph. For example, color, node types and similarity based topic clustering. During this period, we have applied our novel approach to exploration of a diverse set of heterogeneous data sources, including a large corpus of awarded NSF grants, a collection of about ten thousand research papers from the California Institute for Telecommunications and Information Technology (CalIT2), the 2009 US Health bill, as well as the initial program plan of this Collaborative Technology Alliance (cf. Figure 3). During this period, we have also researched new ways to use interactive graph manipulation (e.g. selection, filtering, and expansion of result sets; grouping nodes and highlighting relationships by interactive dragging) as a control mechanism for complex data mining algorithms. (Gretarsson et al. 2010)
The above three projects are supported in the INARC APP in I2.
Participants:
-
Kathy Macropol
- Ambuj Singh
- Brynjar Gretarsson
- Xifeng Yan
- Arijit Khan
- Collaboration with Charu Aggarwal (IBM)
Publications:
- Macropol and Singh, 2010
- Gretarsson et al., 2010
- Aggarwal et al., 2011
Back to top